Inherent risk… residual risk… current risk? When your risk manager or regulatory affairs asks about your “inherent risk”, it highlights a fundamental flaw in qualitative risk assessments. Here’s why – and how to fix it.
Although most of us engage in some form of risk management daily, the term risk and associated terms such as inherent risk or residual risk do not rely on a shared, agreed-upon definition. This is perhaps most clearly shown in the ISO 31000:2018 standard for risk management, where risk is defined as “effect of uncertainty on objectives” followed by three footnotes, arguing that this can be both positive and negative outcomes, ending in the compromise that “Risk is usually expressed in terms of risk sources, potential event, their consequences and their likelihood”. If we look to ISO 27000:2018, it’s even worse.
In this article, we present three common states of risk. We uncover why inherent risk, despite good intentions, is difficult and, in some cases, meaningless to work with. In addition, we show how quantitative risk assessments make inherent risk irrelevant, and can improve the quality of your risk assessments.
We have already written about how to write a good risk scenario, so go ahead and read that article after this one.
We define risk in relation to information security as “The probable frequency and probable magnitude of a future loss” (O-RT v3.0). This definition is compatible with both the FAIR methodology and risk management techniques as described in ISO 27005 or ISO 31010. That is, we study risk as a composite of a consequence and its associated likelihood or frequency.
Risk management is, then, the iterative process of understanding (measuring) your risk exposure and taking actions (treatment) to ensure your risk remains within an acceptable threshold.
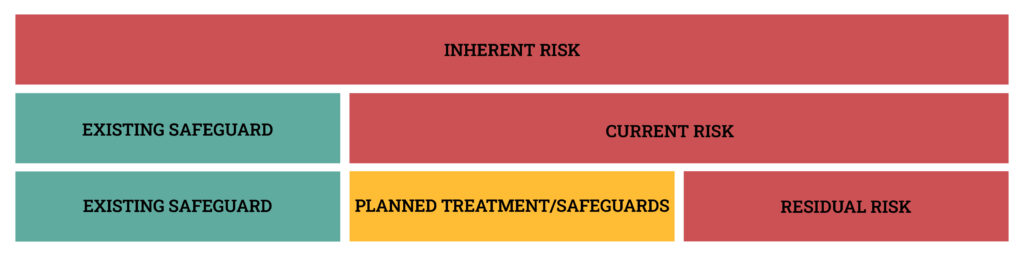
To do this, we talk about risk in different states.
- Inherent risk is the risk associated with an asset or event, in the absence of safeguards/controls.
- Current risk is the risk associated with an asset or event given existing safeguards/controls.
- Residual risk is the risk remaining after risk treatment.
THE MISSING RISK
In some fields – especially within data privacy and GDPR – you will see regulators requiring that you consider inherent risk. Similar requirements appear within related information security fields. The reason for this is best described in the following examples:
Example 1
For the protection of personal data, it is not sufficient to consider current risk. You must also consider the risk to the data subject, given that an event occurs where personal information is leaked (e.g. a Data Protection Impact Assessment or DPIA). That is without regard for existing safeguards.
In this example, it is important to note, that the risk is that of the data subject, and not the company. It is an entirely different context from enterprise information risk. The company may experience risk related to such a scenario, but it will be different from the risk faced by the data subject.
Example 2
A large company registers and manages hundreds of risk scenarios across the organization. Individual departments are responsible for evaluating their risk in a qualitative risk matrix. If the risk is red, it must be reported to management. Such a risk assessment frequently considers current risk (although sometimes called inherent risk) or residual risk. You must report your risk to management only if you are unable to reduce the risk level to below your acceptance criteria (e.g. residual risk is yellow or green). Consequently, the organization may operate with several risk scenarios that in terms of inherent or current risk are above company tolerances, but are never reported to management, as the residual risk is green.
In effect, the board of directors do not have an accurate picture of the actual risk exposure of the organization. A significant loss event that can cost the company millions of dollars may be reduced to yellow or even green in a risk matrix because of the effective safeguards that are in place, leading to a low likelihood. On the opposite end of the spectrum, a much smaller loss event with higher likelihood may become yellow or even red, given the high likelihood. The first event will not be reported to management, while the second event will be reported. Does this mean that loss event 2 is more important for the board of directors to consider?
The issue presented in example 2 is where we start seeing regulators requiring that organizations actively consider inherent risk, and report on this. This is done for two reasons. A) To ensure that a substantial inherent risk is not overlooked by upper management, and B) to consider that risk treatments that are planned or already implemented may fail. In other words: What is the risk if a malicious actor manages to get into your system despite your 2FA and audits?
WHY QUANTITATIVE RISKS DON’T GO MISSING
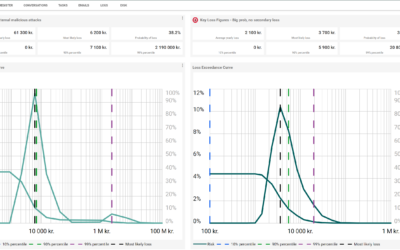
The first problem – that risks disappear from the overall risk picture presented to management – does not exist in a FAIR-based quantitative risk assessment. Regardless of how much you reduce a risk, it does not disappear from the combined reporting, and remains a part of the aggregated loss exceedance curve. Because quantitative risks can be aggregated mathematically, current risk can be reported at any level of the organization, without losing detail, and thus provide a more accurate risk picture.
The other problem – that safeguards can fail – is built into the estimates with 90% confidence intervals that make up the risk scenarios. No matter how many safeguards you implement, there will always be a residual risk, which covers an event where your safeguards fail, or where they work but are insufficient. This uncertainty about outcomes is built into the 90% confidence intervals and is aggregated in a way, that no detail is lost in your risk report. The very unlikely scenario with massive losses can still be viewed from the aggregated loss distributions, as we move towards the tail of the loss distribution.
THE PROBLEM WITH INHERENT RISK
Okay. We now know that inherent risk can be a necessary component of a qualitative risk assessment as qualitative risks cannot be aggregated in a meaningful way, causing some risks to disappear from view. We also know that the quantitative risk assessment – if done right – does not suffer from the same problems. But is that the whole reason why we insist on not calculating inherent risk?
No. Firstly, inherent risk is not as universal as you may think. For instance, inherent risk is not included in standards, such as ISO 31000 or ISO 27000. The main flaw of inherent risk is that when used in practice, it does not explicitly consider which controls are being included or excluded. A truly inherent risk state in information security would be to leave all your company information in a publicly accessible location. This risk scenario would be of very limited value to your organization. As Dr Carl Gibson puts it: ”If all controls are removed, then any modelling of risk will trend to the highest possible consequence with an almost certain probability. How does this add value to any risk assessment?”
You might then say; let’s set a limit to which safeguards are part of the inherent risk level. E.g. your inherent risk is risk with any controls implemented 2 or more years ago. That is a slippery slope. It still exposes you to the fallacy of example 2 above and hardly provides meaningful input to your current risk assessment.
Inherent risk (in information security), as defined in this article, is a less-than-useful term that adds to the confusion around states of risk, and is implemented mainly to cover for the failure of qualitative risk models.
A (QUANTITATIVE) WAY FORWARD
When we conduct a quantitative IT risk assessment with our clients, our focus is on the current risk. We interview subject matter experts and measure on the risk landscape as-is with the currently implemented safeguards/controls. We then present recommendations to address any areas where the risk appetite or tolerance is surpassed, and calculate the expected risk reduction (Current risk – residual risk).
Our measures of current risk – ranges with a 90% confidence interval – ensure that we take into account events that fall outside the estimated ranges. These events are all visible on the loss distributions that we report.
The idea of studying specific risks in extreme cases can still be a useful exercise. You may want to dive deeper into specific risk areas. Perhaps you want to know how expensive a specific event can be, or how expensive an actual incident was. Rather than calling this inherent risk, we recommend talking about inherent probable consequence or consequence, given a loss event. That is, we study only the consequence-side of the risk formula, and disregard the likelihood of the incident happening entirely. Such an exercise should still produce ranges of loss, reflecting our uncertainty about loss magnitude, but allow us to study the “worst case” situations that we find of particular importance to us.
In summary, there are three states of risk: Inherent, current, and residual risk. The definitions are blurry at best, and inherent risk in its most pure form is practically irrelevant when conducting quantitative risk assessments.
If you want to learn more about how you can implement scientifically sound risk management practices in your organisation, feel free to reach out to us.
Be sure also to check out our free webinar on march 23rd 2023, where we provide a comprehensive introduction to quantitative risk management.